Battling
Competitive Pokémon Battle Bots
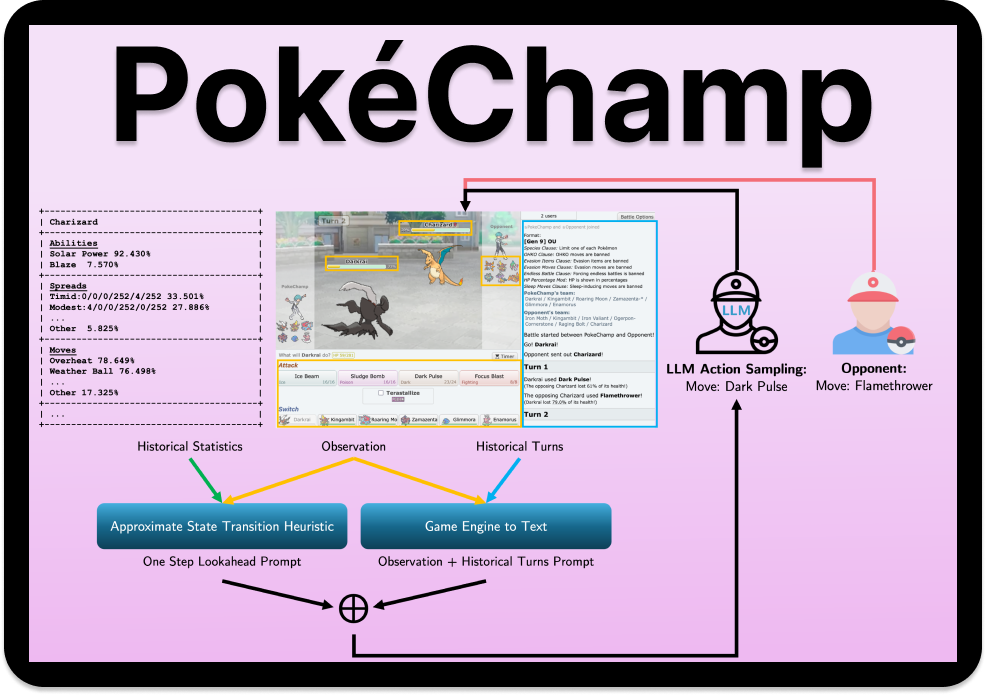
Pokémon Showdown is an open-source simulator that transforms Pokémon's turn-based battles into a competitive strategy game enjoyed by thousands of daily players. Competitive Pokémon battles are two-player stochastic games with imperfect information, where players build teams and navigate complex battles by mastering nuanced gameplay mechanics and making decisions under uncertainty.
Advances in language models, large-scale reinforcement learning datasets, and accessible open-source tools have attracted a growing community of ML researchers to this problem. Recent methods have achieved human-level gameplay in popular singles rulesets. How much further can we push the capabilities of Competitive Pokémon AI?
New to Pokémon Showdown? Read an intro guide for ML researchers